《强化学习》学习笔记(一)
Chap 1. 导论
- 强化学习的基本思想
- 在智能体为了实现目标而不断与环境产生交互的过程中,抓住智能体所面对的真实问题的主要方面。
- 具备学习能力的智能体必须能够在某种程度上感知环境的状态,然后采取动作影响环境状态。
- 智能体必须同时拥有和环境状态相关的一个或多个明确的目标。
- 马尔科夫决策过程包含这三个方面
- 感知、动作、目标
- 强化学习要素
- 策略
- 定义了学习智能体在特定时间的行为方式,环境状态到动作的映射
- 收益信号
- 定义了强化学习问题中的目标,表明短时间内什么是好的(基本由环境直接给予)
- 价值函数
- 表明了从长远的角度看什么是好的,可理解为对将来收益累加起来的期望(需要综合评估,难以确定)
- 对环境建立的模型
- 给定状态和动作,模型预测外部环境的下一个状态和收益(环境模型被用于做规划)
- 策略
- Marvm Minsky 在他的博士论文中(Minsky, 1954)讨论了强化学习的计算方法,描述了他组装的一 台基于模拟信号的机器,他称其为“随机神经模拟强化计算器“, SNARCs(Stochastic Neural-Analog Reinforcement Calculators),模拟可修改的大脑突触连接(第15章)
第一部分 表格型求解方法
Chap 2. 多臂赌博机
-
$k$臂赌博机问题
-
学习问题:
- 重复地在$k$个选项或动作中进行选择。每一个时刻,选择某一个动作(臂),得到一定数值收益,收益仅由选择的动作对应的平稳概率分布决定。目标是某一段时间内最大化总收益的期望
-
动作-价值函数
- \[q_\ast(a)=\mathbb E[R_t\vert A_t=a]\\ Q_t(a)=\frac{t时刻前执行动作a得到的收益总和}{t时刻前执行动作a的次数}=\frac{\sum_{i=1}^{t-1}R_i\cdot \mathbb 1_{A_i=a}}{\sum_{i=1}^{t-1}\mathbb 1_{A_i=a}}\]
-
贪心
- $A_t=\underset{a}{\arg\max}\ Q_t(a)$
-
增量式更新
- \[\begin{align} Q_{t+1}&=\frac{1}{t}\sum_{i=1}^tR_i\\ &=Q_t+\frac{1}{t}[R_t-Q_t] \end{align}\]
-
-
基于置信度上界的动作选择
- $\epsilon-$贪心会尝试选择非贪心动作,但是是盲目的。在非贪心动作中,最好是根据他们的潜力来选择事实上是最优的动作,这要考虑动作对应的估计价值以及这些估计的不确定性(或方差)
- $A_t=\underset{a}{\arg\max}\Big[Q_t(a)+c\sqrt{\frac{\ln t}{N_t(a)}}\Big]$
- $N_t(a)$表示时刻$t$之前动作$a$被选择的次数,$c$控制试探的程度
- $\epsilon-$贪心会尝试选择非贪心动作,但是是盲目的。在非贪心动作中,最好是根据他们的潜力来选择事实上是最优的动作,这要考虑动作对应的估计价值以及这些估计的不确定性(或方差)
-
梯度赌博机算法
-
偏好函数$H_t(a)$
- $\Pr {A_t=a}=\frac{e^{H_t(a)}}{\sum_{b=1}^ke^{H_t(b)}}=\pi_t(a)$
- $\pi_t(a)$表示$a$在时刻$t$被选择的概率
-
更新
-
选择动作$A_t$并获得收益$R_t$后进行如下更新 \(\begin{align} H_{t+1}(A_t)&=H_t(A_t)+\alpha(R_t-\overline R_t)(1-\pi_t(A_t))\\ H_{t+1}(a)&=H_t(a)-\alpha(R_t-\overline R_t)\pi_t(a),\ \ \ \ a\neq A_t \end{align}\)
-
$\overline R_t$是在时刻$t$内所有收益的平均值,如果收益高于均值,则未来选择的概率增大,反之减小
-
-
梯度上升算法
-
要使总体收益期望$\mathbb E[R_t]=\sum_x\pi_t(x)q_\ast(x)$最大
-
有更新方程: \(\\ H_{t+1}(a)=H_t(a)+\alpha\frac{\partial\mathbb E[R_t]}{\partial H_t(a)}\\\)
-
求解梯度
- \[\begin{align} \frac{\partial \mathbb E[R_t]}{\partial H_t(a)}&=\frac{\partial}{\partial H_t(a)}\Big[\sum_x\pi_t(x)q_\ast(x)\Big]\\ &=\frac{\partial}{\partial H_t(a)}\Big[\sum_x\pi_t(x)\big(q_\ast(x)-B_t\big)\Big]\\ &=\sum_x(q_\ast(x)-B_t)\frac{\partial \pi_t(x)}{\partial H_t(a)}\\ &=\sum_x\pi_t(x)(q_\ast(x)-B_t)\frac{\partial \pi_t(x)}{\partial H_t(a)}/\pi_t(x)\\ &=\mathbb E\Big[(q_\ast(A_t)-B_t)\frac{\partial \pi_t(A_t)}{\partial H_t(a)}/\pi_t(A_t)\Big]\\ &=\mathbb E\Big[(R_t-\overline R_t)\frac{\partial \pi_t(A_t)}{\partial H_t(a)}/\pi_t(A_t)\Big]\\ &=\mathbb E\Big[(R_t-\overline R_t)\pi_t(A_t)\big(\mathbb 1_{a=A_t}-\pi_t(A_t)\big)/\pi_t(A_t)\Big]\\ &=\mathbb E\Big[(R_t-\overline R_t)\big(\mathbb 1_{a=A_t}-\pi_t(A_t)\big)\Big] \end{align}\]
- 其中$\mathbb 1_{a=A_t}$表示如果$a=A_t$取$0$,否则取$1$
-
-
Chap 3. 有限马尔可夫决策过程(有限Markov Decision Process, MDP)
-
“环境”输出状态和收益,“智能体”输出动作,环境和智能体一同生成序列/轨迹:状态、动作、收益、状态……
-
有限MDP中,状态、动作和收益的集合都只有有限个元素,在这种情况下,收益和状态具有明确的离散概率分布,并且只依赖于前继状态和动作。
-
函数$p$定义了MDP的动态特性
- \[p(s',r\vert s,a)\overset{.}=\mathrm{Pr}\{S_t=s',R_t=r\vert S_{t-1}=s,A_{t-1}=a\}\]
-
状态转移概率
- \[p(s'|s,a)\overset{.}{=}\mathrm {Pr}\{S_t=s'\vert S_{t-1}=s,A_{t-1}=a\}=\sum_{r\in \mathcal R}p(s',r\vert s,a)\\\]
-
”状态-动作“二元组期望收益
- \[r(s,a)\overset{.}{=}\mathbb E[R_t\vert S_{t-1}=a,A_{t-1}=a]=\sum_{r\in \mathcal R}r\sum_{s'\in\mathcal S}p(s',r\vert s,a)\]
-
“状态-动作-后继动作”三元组期望收益
- \[r(s,a,s')\overset{.}=\mathbb E[R_t\vert S_{t-1}=s,A_{t-1}=a,S_t=s']=\sum_{r\in \mathcal R}r\frac{p(s',r'\vert s,a)}{p(s'\vert s,a)}\]
-
-
分幕式任务:智能体和环境的交互能被自然分成一系列子序列(每个子序列都存在最终时刻)
-
称每个子序列为幕(episode),每幕都以一种特殊状态结束,称之为终结状态。
-
这样的任务中可以设置回报是收益的总和
- \[G_t\overset{.}=R_{t+1}+R_{t+2}+\dots+R_T\]
-
-
持续性任务:不能被自然地分为单独的幕,而是持续不断地发生
-
由于$T=\infty$此时回报不能设置为总和,可以引入一个折扣率$\gamma$
- \[G_t\overset{.}=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots=\sum_{k=0}^{\infty}\gamma^kR_{t+k+1}\\ G_t=R_{t+1}+\gamma G_{t-1}\]
- 其中$0\leq\gamma\leq1$,被称为折扣率
-
- 分幕式和持续性任务的统一表示法
- 将幕单独拿出来,$S_t$表示某一幕中时刻$t$的状态(即每一幕开始时刻都是$t=0$)
- 将分幕式任务中的终结状态当作一个特殊的吸收状态入口,即只会转移到自己并且只产生零收益(即$T=\infty$)
- 显然$\gamma=1$时的持续性任务表示与分幕式任务一致
-
策略和价值函数
-
价值函数是状态(或状态与动作二元组)的函数,用来评估当前智能体在给定状态(或给定状态与动作)下有多好(用未来预期收益来定义)
-
策略是从状态到每个动作的选择概率之间的映射。如果智能体在时刻$t$选择了策略$\pi$,那么$\pi(a\vert s)$就是当$S_t=s$时$A_t=a$的概率
-
状态价值函数:将策略$\pi$下状态$s$的价值函数记为$v_\pi(s)$,即从状态$s$开始,智能体按照策略$\pi$进行决策所获得的回报的概率期望值。对于MDP
- \[v_\pi(s)\overset.=\mathbb E[G_t\vert S_t=s]=\mathbb E_\pi\Big[\sum_{k=0}^\infty\gamma^kR_{t+k+1}\Big\vert S_t=s\Big]\]
-
动作价值函数:将策略$\pi$下在状态$s$时采取动作$a$的价值记为$q_\pi(s,a)$。这就是根据策略$\pi$,从状态$s$开始,执行动作$a$之后,所有可能的决策序列的期望回报
- \[q_\pi(s,a)\overset.=\mathbb E[G_t\vert S_t=s,A_t=a]=\mathbb E\Big[\sum_{k=0}^\infty\gamma^kR_{t+k+1}\Big\vert S_t=s,A_t=a\Big]\]
-
价值函数$v_\pi$和$q_\pi$都能从经验中估算得到,如果一个智能体遵循策略$\pi$,并且对每个遇到的状态都记录该状态后的实际回报的平均值,那么 随着状态出现次数接近无穷大,这个平均值会收敛到状态价值$v_\pi(s)$($q_\pi(s,a)$同理)。这种估算方法称作蒙特卡洛方法 。
-
对于任何策略$\pi$和任何状态$s$,$s$的价值与其可能的后继状态的价值之间存在以下关系
- \[\begin{align} v_\pi(s)\overset.=&\mathbb E_\pi[G_t\vert S_t=s]\\ =&\mathbb E_\pi[R_{t+1}+\gamma G_{t+1}\vert S_t=s]\\ =&\sum_a\pi(a\vert s)\sum_{s'}\sum_rp(s',r\vert s,a)\Big[r+\gamma\mathbb E_\pi[G_{t+1}\vert S_{t+1}=s']\Big]\\ =&\sum_a\pi(a\vert s)\sum_{s',r}p(s',r\vert s,a)\Big[r+\gamma v_\pi(s')\Big] \end{align}\]
- 上式最后一行被称作$v_\pi$的贝尔曼方程,价值函数$v_\pi$是贝尔曼方程的唯一解
-
-
最优策略和最优价值函数
-
对于有限MDP,可以通过比较价值函数精确地定义一个最优策略。如果要说一个策略$\pi$不比另一个策略$\pi’$差甚至比它更好,那么其所有状态上的期望回报都应该等于或大于$\pi’$的期望回报。即
- 若对于所有$s\in\mathcal S,\ v_\pi(s)\geq v_{\pi’}(s)’$,则有$\pi\geq\pi’$
-
总会存在至少一个策略不劣于其他所有的策略,这就是最优策略(可能不止一个),用$\pi_\ast$来表示所有这些最优策略。他们共享相同的状态价值函数,称之为最优状态价值函数,记为$v_\ast$。也共享相同的最优动作价值函数,记为$q_\ast$
- \[v_\ast(s)\overset.=\underset \pi\max v_\pi(s)\\ q_\ast(s,a)\overset.=\underset \pi\max q_\pi(s,a)\\ q_\ast(s,a)=\mathbb E[R_{t+1}+\gamma v_\ast(S_{t+1})\big \vert S_t=s,A_t=a]\]
-
因为$v_\ast$是策略的价值函数,它必须满足贝尔曼方程中状态和价值的一致性条件。但因为它是最优的价值函数,因此$v_\ast$的一致性条件可以用一种特殊的形式表示,而不拘泥于特定的策略。这就是贝尔曼最优方程(最优策略下各个状态的期望一定等于这个状态下最优动作的期望回报)
- \[\begin{align} v_\ast(s)&=\underset{a\in\mathcal A(s)}\max q_{\pi_\ast}(s,a)\\ &=\underset a\max\mathbb E_{\pi_\ast}[G_t\vert S_t=s,A_t=a]\\ &=\underset a\max\mathbb E_{\pi_\ast}[R_{t+1}+\gamma G_{t+1}\vert S_t=s,A_t=a]\\ &=\underset a\max\mathbb E[R_{t+1}+\gamma v_\ast(S_{t+1})\vert S_t=s,A_t=a]\\ &=\underset a\max \sum_{s',r}p(s',r\vert s,a)[r+\gamma v_\ast(s')] \end{align}\]
- 最后两个等式就是$v_\ast$的贝尔曼最优方程的两种形式。
-
$q_\ast$的贝尔曼最优方程如下
- \[\begin{align} q_\ast(s,a)&=\mathbb E\Big[R_{t+1}+\gamma \underset {a'}\max q_\ast(S_{t+1},a')\Big\vert S_t=s,A_t=a\Big]\\ &=\sum_{s',r}p(s',r\vert s,a)[r+\gamma \underset{a'}\max q_\ast(s',a')] \end{align}\]
-
- 最优性和近似算法
- 在状态集合小而有限的任务中,用数组或表格来估计每个状态是有可能的,这种任务称为表格型任务,对应的方法称作表格型方法
- 但在很多实际情况下,经常有很多状态是不能用表格中的一行来表示的。因此价值函数必须采用近似算法,通常使用紧凑的参数化函数表示方法
- 小结
- 智能体与环境在一连串的离散时刻进行交互。两者之间的接口定义了一个特殊的任务:
- 动作由智能体来选择,状态是做出选择的基础,而收益是评估选择的基础。
- 策略是一个智能体选择动作的随机规则,它是状态的一个函数。
- 智能体与环境在一连串的离散时刻进行交互。两者之间的接口定义了一个特殊的任务:
最优决策定理证明:
-
定理:
- 定义策略的偏序$\pi\geq\pi’\ \mathrm {if}\ v_\pi(s)\geq v_{\pi’}(s),\forall s$
- 定理1:一定存在一个最优策略$\pi_\ast$,使得对任意策略$\pi$有$\pi_\ast\geq\pi$
- 定理2:所有最优策略都有相同、最优的价值函数,即$v_{\pi_\ast}=v_\ast(s)$
- 定理3:所有最优策略都有相同、最优的动作价值函数,即$q_{\pi_\ast}(s,a)=q_\ast(s,a)$
-
贝尔曼最优方程存在唯一解证明
-
由于状态数量有限,因此价值函数可以看作是一个维度为状态集大小的价值向量
- \[V = \{v(s):s\in \mathcal S\}\in \mathbb R^{\vert\mathcal S\vert}\]
-
根据最优价值函数定义推导贝尔曼最优方程:
- \[\begin{align} v_*(s)&\overset.=\underset{\pi}{\max}\ v_{\pi}(s)\nonumber\\ &=\underset{a\in\mathcal A(s)}\max q_{\pi_*}(s,a)\nonumber\\ &=\underset a\max\ \mathbb E_{\pi_*}[G_t\vert S_t=s,A_t=a]\nonumber\\ &=\underset a\max\ \mathbb E_{\pi_*}[R_{t+1}+\gamma G_{t+1}\vert S_t=s,A_t=a]\nonumber\\ &=\underset a\max\ \mathbb E[R_{t+1}+\gamma v_*(S_{t+1})\vert S_t=s,A_t=a]\nonumber\\ &=\underset a\max\ \sum_{s',r}p(s',r\vert s,a)[r+\gamma v_*(s')]\nonumber \end{align}\]
-
将贝尔曼最优方程看作是价值向量空间的映射$T$,则有
- \[\begin{align} &T:\mathbb R^{\vert\mathcal S\vert}\rightarrow\mathbb R^{\vert\mathcal S\vert}\nonumber\\ &TV=\Big\{\underset a\max\ \sum_{s',r}p(s',r\vert s,a)[r+\gamma v(s')]:s\in\mathcal{S}\Big\}\nonumber \end{align}\]
-
对于任意两个价值向量$V,V’$有
- \[\begin{align} \parallel TV-TV'\parallel_\infty&\overset.=\underset{s\in\mathcal S}{\max}\Big\vert TV(s)-TV'(s)\Big\vert\nonumber\\ &=\underset{s\in\mathcal S}{\max}\Big\vert \underset a\max\ \sum_{s',r}p(s',r\vert s,a)[r+\gamma v(s')]-\underset a\max\ \sum_{s',r}p(s',r\vert s,a)[r+\gamma v'(s')]\Big\vert\nonumber\\ &\leq\underset{s\in\mathcal S}{\max}\ \underset a\max\ \Big\vert \sum_{s',r}p(s',r\vert s,a)[r+\gamma v(s')]-\sum_{s',r}p(s',r\vert s,a)[r+\gamma v'(s')]\Big\vert\nonumber\\ &=\gamma\underset{s\in\mathcal S}{\max}\ \underset a\max\ \Big\vert \sum_{s',r}p(s',r\vert s,a)\big[v(s')- v'(s')\big]\Big\vert\nonumber\\ &\leq\gamma\underset{s\in\mathcal S}{\max}\ \underset a\max\ \sum_{s',r}p(s',r\vert s,a)\Big\vert v(s')- v'(s')\Big\vert \nonumber\\ &\leq\gamma\underset{s\in\mathcal S}{\max}\ \underset a\max\ \sum_{s',r}p(s',r\vert s,a)\max_{s''\in \mathcal S}\Big\vert v(s'')- v'(s'')\Big\vert \nonumber\\ &=\gamma\max_{s''\in \mathcal S}\Big\vert v(s'')- v'(s'')\Big\vert \nonumber\\ &=\gamma \parallel V-V'\parallel_\infty\nonumber \end{align}\]
-
由于$\gamma<1$,$T$是一个收缩映射。则对于任意$V,V’$,有
- \[\begin{align} \underset{n\rightarrow \infty}\lim\parallel T^nV-T^nV'\parallel_\infty=0\nonumber\\ V_*=\underset{n\rightarrow \infty}\lim T^nV=\underset{n\rightarrow \infty}\lim T^nV'\nonumber\\ TV_*=T\underset{n\rightarrow \infty}\lim T^nV=V_*\nonumber \end{align}\]
-
则$V_\ast$为贝尔曼最优方程的解。
假设存在多个$V_\ast$,则所有$\parallel V_{\ast i} - V \parallel_{\infty}$都要随迭代同时下降,矛盾,因此$V_\ast$唯一。
综上:$v_\ast(s)\overset.=\underset{\pi}{\max}\ v_{\pi}(s)$存在且唯一。
-
-
贝尔曼方程存在唯一解证明
-
根据价值函数定义推导贝尔曼方程:
- \[\begin{align*} v_\pi(s)\overset.=&\mathbb E_\pi[G_t\vert S_t=s]\\ =&\mathbb E_\pi[R_{t+1}+\gamma G_{t+1}\vert S_t=s]\\ =&\sum_a\pi(a\vert s)\sum_{s'}\sum_rp(s',r\vert s,a)\Big[r+\gamma\mathbb E_\pi[G_{t+1}\vert S_{t+1}=s']\Big]\\ =&\sum_a\pi(a\vert s)\sum_{s',r}p(s',r\vert s,a)\Big[r+\gamma v_\pi(s')\Big] \end{align*}\]
-
类似地,将贝尔曼方程看作是价值向量空间的映射$T$,推导得到
- \[\begin{align} \parallel TV-TV'\parallel_\infty&\overset.=\underset{s\in\mathcal S}{\max}\Big\vert TV(s)-TV'(s)\Big\vert\nonumber\\ &\leq\gamma \parallel V-V'\parallel_\infty\nonumber \end{align}\]
-
同理得到结论:贝尔曼方程有唯一解$v(s)$
即:当策略$\pi$确定,则存在唯一的价值函数$v_\pi$与之对应
-
-
定理1证明
-
对任意状态$s$,找到$a_\ast\in\mathcal A(s)$,使得
- \[\begin{align} &\forall a'\in \mathcal A(s)\nonumber\\ &\sum_{s',r}p(s',r\vert s,a_*)[r+\gamma v_*(s')]\geq\sum_{s',r}p(s',r\vert s,a')[r+\gamma v_*(s')]\nonumber \end{align}\]
-
构造策略
- \[\begin{equation} \pi(a\vert s)=\left\{ \begin{aligned} 1&,\ a=a_*\\ 0&,\ a\neq a_* \end{aligned} \right.\nonumber \end{equation}\]
-
令$v_\pi(s)=v_\ast(s)$
则有
- \[\begin{align*} v_*(s)&=\underset{a}{\max}\sum_{s',r}p(s',r\vert s,a)\Big[r+\gamma v_*(s')\Big]\\ &=\sum_a\pi(a\vert s)\sum_{s',r}p(s',r\vert s,a)\Big[r+\gamma v_\pi(s')\Big]\\ \end{align*}\]
-
满足贝尔曼方程,因此$v_\ast(s)$是$v_\pi(s)$的唯一解
- \[v_\pi(s)=v_*(s)\geq v_{\pi'}(s),\ \forall s,\pi'\]
- 因此,一定存在一个最优策略$\pi_\ast$不劣于其他任何策略
-
-
定理2证明
-
假设$\pi$对应的价值函数$v_\pi(s)\neq v_\ast(s)$
根据最优价值函数的唯一性与最优性,有
- \[\begin{align*} v_*(s)\geq v_\pi(s),\ \forall s\\ v_*(s)>v_\pi(s),\ \exists s \end{align*}\]
-
因此$\pi_\ast>\pi$,$\pi$一定不是最优策略
即:最优策略$\pi_\ast$一定满足$v_{\pi_\ast}=v_\ast(s)$
-
-
定理3证明
-
对任意最优策略$\pi_\ast$,有
- \[v_{\pi_*}(s)=v_*(s)\]
-
则有动作价值函数
- \[\begin{align*} q_{\pi_*}(s,a)&\overset.=\mathbb E[G_t\vert S_t=s,A_t=a]\\ &=\mathbb E[R_{t+1}+\gamma v_{\pi_*}(S_{t+1})\big \vert S_t=s,A_t=a]\\ &=\mathbb E[R_{t+1}+\gamma v_*(S_{t+1})\big \vert S_t=s,A_t=a]\\ &=\underset \pi\max\ q_\pi(s,a)\\ &=q_*(s,a) \end{align*}\]
- 即:最优策略$\pi_\ast$一定满足$q_{\pi_\ast}=q_\ast(s)$
-
Chap 4. 动态规划
- 动态规划(Dynamic Programming , DP)是一类优化方法,在给定一个用马尔可夫决策过程描述的完备环境模型的情况下,其可以计算最优的策略。
- 传统DP作用有限,原因:
- 完备的环境模型只是一个假设
- 计算复杂度极高
- 事实上,所有其他算法都是对DP的一种近似,只是降低了计算复杂度以及减弱了对环境模型完备性的假设
- 传统DP作用有限,原因:
-
策略估计(预测)
- 思考对于任意一个策略$\pi$,如何计算其状态价值函数$v_\pi$,这在DP文献中被称为策略估计
- 贝尔曼方程唯一解的证明中已经证明对任意策略能通过贝尔曼方程迭代收敛到唯一解。
- 这个算法被称作迭代策略估计
- 思考对于任意一个策略$\pi$,如何计算其状态价值函数$v_\pi$,这在DP文献中被称为策略估计
-
策略改进
-
考虑已有策略$\pi$,只修改某一个状态$s$的动作选择策略改为$\pi’(s,a)$并保持其他状态的策略不变,若此时有$v_{\pi’}(s)>v_\pi(s)$,则有策略$\pi’$优于$\pi$。对于修改多个状态的策略也是类似。
-
根据原策略的价值函数执行贪心算法来构造更好策略,这个过程被称为策略改进。
- \[\begin{align} \pi'(s)\overset.=\underset a {\arg\max}\ q_\pi(s,a) \end{align}\]
-
-
策略迭代
-
一旦一个策略$\pi$根据$v_\pi$产生一个更好的策略$\pi’$,可以计算$v_{\pi’}$来得到一个更优的策略$\pi’’$,迭代得到一个不断改进的策略和价值函数序列
- \[\pi_0\overset {\mathrm E}\rightarrow v_{\pi_0}\overset {\mathrm I}\rightarrow \pi_1\overset {\mathrm E}\rightarrow v_{\pi_1}\overset {\mathrm I}\rightarrow \cdots \overset {\mathrm I}\rightarrow \pi_*\overset {\mathrm E}\rightarrow v_*\]
-
$\overset {\mathrm E}\rightarrow$代表策略评估,$\overset {\mathrm I}\rightarrow$代表策略改进
- 这种寻找最优策略的方法叫作策略迭代
-
-
价值迭代
-
策略迭代的一个缺点就是每次迭代都涉及了策略评估。但实际上在策略评估的迭代求解中,在一定步数之后即使价值函数有变化,贪心策略不一定会变化,因此可以提前结束策略评估过程。
-
可以每次在一次遍历后就停止策略评估,这样的算法称为价值迭代
- \[\begin{align} v_{k+1}\overset .=&\underset a\max\mathbb E[R_{t+1}+\gamma v_k(S_{t+1})\vert S_t=s,A_t=a]\\ =&\underset a\max \sum_{s',r}p(s',r\vert s,a)[r+\gamma v_k(s')] \end{align}\]
-
-
异步动态规划
- 前面讨论的DP方法有个主要缺点,涉及对MDP的整个状态集的操作,因此如果状态集很大,即便单次遍历也会需要非常多的时间。
- 异步DP算法是一类就地迭代的DP算法,比如用价值迭代的更新公式,但在每一步$k$上都只更新状态$s_k$的值。
-
广义策略迭代
- 用广义策略迭代(GPI)一词来指代让策略评估和策略改进相互作用的一般思路,与这两个流程的粒度和其他细节无关。
- 比如策略迭代是策略评估和策略改进交替进行的,可以修改其中的一些细粒度,如提前结束策略评估的迭代。
- 可以将GPI的评估和改进流程看作是两个约束或目标之间相互作用的流程
- 只要在迭代的过程中$v$的改变会让$\pi$更接近$\pi_\ast$,$\pi$的改变让$v$更接近$v_\ast$,最后算法就会收敛。
- 用广义策略迭代(GPI)一词来指代让策略评估和策略改进相互作用的一般思路,与这两个流程的粒度和其他细节无关。
-
动态规划的效率
- 小结
- DP算法有个特殊性质:所有的方法都根据对后继状态价值的估计,来更新对当前状态价值的估计。
- 这种普遍的思想称为自举法(bootstrapping)
- DP算法有个特殊性质:所有的方法都根据对后继状态价值的估计,来更新对当前状态价值的估计。
Chap 5. 蒙特卡洛方法(Monte Carlo Methods)
- 本章中考虑第一类估计价值函数并寻找最优策略的使用算法
- 蒙特卡洛算法仅仅需要经验,不需要假设拥有完备的环境知识。
- 经验:从真实或者模拟的环境交互中采样得到的状态、动作、收益的序列。
- 这样也就不需要关于环境动态变化规律的先验知识
- 通过平均样本的回报来解决强化学习问题
- 分幕式任务
- 蒙特卡洛算法仅仅需要经验,不需要假设拥有完备的环境知识。
-
蒙特卡洛预测
- 给定策略学习价值函数
- 在给定的某一幕中,状态$s$可能出现多次
- 首次访问型MC算法用$s$的所有首次访问的回报的平均值来估计$v_\pi(s)$(本章内容)
- 每次访问型MC算法用$s$的所有访问的回报的平均值来估计$v_\pi(s)$
- 蒙特卡洛算法对于每个状态的估计是独立的,没有使用自举的思想
- DP是根据后继状态的价值函数推导当前状态价值函数
- 蒙特卡洛算法是直接根据状态回报的平均值计算价值函数
-
动作价值的蒙特卡洛估计
- 如果无法得到环境的模型,那么计算动作价值函数更有用一些
- 环境模型:大概可以理解为输入为状态和动作,输出为下一个状态和收益的概率分布(没有环境模型也能够在环境中采样)
- 有模型时选特定动作使得收益与后继状态价值函数之和最大即可
- 无模型则需要显式地确定每个动作的价值函数来确定策略
- 求解方法与状态价值函数求解方法类似,只是变成求(状态,动作)二元组的回报的均值
- 出现新的问题:许多二元组可能不会被访问到
- 试探性出发(exploring starts):将指定的二元组作为起点开始一幕的采样,同时保证所有二元组都有非零的概率被选为起点。
- 如果无法得到环境的模型,那么计算动作价值函数更有用一些
-
蒙特卡洛控制
- 即如何近似最优的策略
- 求解方式与策略迭代类似
- 可以逐幕交替进行评估与改进,如
- 每一幕结束后,使用观测到的回报进行策略评估,然后在每个访问到的状态进行策略改进
- 即如何近似最优的策略
-
没有试探性出发假设的蒙特卡洛控制
- 同轨策略(on-policy)/离轨策略(off-policy):生成采样数据序列的策略和用于实际决策的待评估和改进的策略是相同/不同的
- 离轨即生成的数据“离开”了待优化的策略所决定的决策序列轨迹
- 同轨策略一般使用$\epsilon-$贪心策略
- 同轨策略(on-policy)/离轨策略(off-policy):生成采样数据序列的策略和用于实际决策的待评估和改进的策略是相同/不同的
-
基于重要度采样的离轨策略
-
为了搜索所有的动作,需要采取非最优的策略
- 目标策略$\pi$:需要估计的策略
- 行动策略$b$:采样使用的策略
-
重要度采样
-
希望估计的是目标策略$\pi$下的期望回报,但我们只有行动策略$b$下的回报$G_t$(回报的值相同,但是两策略下发生的概率不同)
-
因此设置一个重要度,表示采样得到的决策序列在$\pi$下的概率与在$b$下的概率的比值
- \[\rho_{t:T-1}\overset.=\frac{\Pi_{k=t}^{T-1}\pi(A_k\vert S_k)p(S_{k+1}\vert S_k,A_k)}{\Pi_{k=t}^{T-1}b(A_k\vert S_k)p(S_{k+1}\vert S_k,A_k)}=\frac{\Pi_{k=t}^{T-1}\pi(A_k\vert S_k)}{\Pi_{k=t}^{T-1}b(A_k\vert S_k)}\]
-
则有$v_\pi(s)=\mathbb E[\rho_{t:T-1}G_t\vert S_t=s]$
- 该期望可以取$\rho_{t:T-1}G_t$的均值(普通重要度采样,方差无穷大)$\frac{\sum_{t\in \mathcal T(s)}\rho_{t:T(t)-1}G_t}{\vert\mathcal T(s)\vert}$
- 也可以是权重为$\rho_{t:T-1}$下$G_t$的加权均值(加权重要度采样,方差逐渐收敛到零)$\frac{\sum_{t\in \mathcal T(s)}\rho_{t:T(t)-1}G_t}{\sum_{t\in\mathcal T(s)}\rho_{t:T(t)-1}}$
-
-
-
增量式实现
-
从
- \[V_n\overset.=\frac{\sum_{k=1}^{n-1}W_kG_k}{\sum_{k=1}^{n-1}W_k},\ n\geq2\]
-
变为
- \[V_{n+1}\overset.=V_n+\frac{W_n}{C_n}[G_n-V_n],\ n\geq1\\ C_{n+1}\overset.=C_n+W_{n+1}\]
-
-
离轨策略蒙特卡洛控制
- 需要选择$\epsilon-$软性的行动策略$b$
-
折扣敏感的重要度采样
-
定义平价部分回报
- \[\overline G_{t:h}\overset.=R_{t+1}+R_{t+2}+\cdots+R_h,\ 0\leq t<h\leq T\]
-
传统的全回报$G_t$可以看作上述平价部分回报的加权和
- \[\begin{align} G_t\overset.=&R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\cdots+\gamma^{T-t-1}R_T\\ =&(1-\gamma)R_{t+1}\\ &+(1-\gamma)\gamma(R_{t+1}+R_{t+2})\\ &+(1-\gamma)\gamma^2(R_{t+1}+R_{t+2}+R_{t+3})\\ &\ \ \vdots\\ &+(1-\gamma)\gamma^{T-t-2}(R_{t+1}+R_{t+2}+\cdots+R_{T-1})\\ &+\gamma^{T-t-1}(R_{t+1}+R_{t+2}+\cdots+R_{T})\\ =&(1-\gamma)\sum_{h=t+1}^{T-1}\gamma^{h-t-1}\overline G_{t:h}+\gamma^{T-t-1}\overline G_{t:T} \end{align}\]
-
此时再对每个$\overline G_{t:h}$考虑重要度
-
折扣敏感的普通重要度采样
- \[V(s)\overset.=\frac{\sum_{t\in\mathcal T(s)}\Big((1-\gamma)\sum_{h=t+1}^{T(t)-1}\gamma^{h-t-1}\rho_{t:h-1}\overline G_{t:h}+\gamma^{T(t)-t-1}\rho_{t:T(t)-1}\overline G_{t:T(t)}\Big)}{\vert\mathcal T(s)\vert}\]
-
折扣敏感的加权重要度采样
- \[V(s)\overset.=\frac{\sum_{t\in\mathcal T(s)}\Big((1-\gamma)\sum_{h=t+1}^{T(t)-1}\gamma^{h-t-1}\rho_{t:h-1}\overline G_{t:h}+\gamma^{T(t)-t-1}\rho_{t:T(t)-1}\overline G_{t:T(t)}\Big)}{\sum_{t\in\mathcal T(s)}\Big((1-\gamma)\sum_{h=t+1}^{T(t)-1}\gamma^{h-t-1}\rho_{t:h-1}+\gamma^{T(t)-t-1}\rho_{t:T(t)-1}\Big)}\]
-
-
-
每次决策型重要度采样
-
\[\begin{align}
\rho_{t:T-1}G_t=&\rho_{t:T-1}(R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{T-t-1}R_T)\\
=&\rho_{t:T-1}R_{t+1}+\gamma\rho_{t:T-1}R_{t+2}+\cdots+\gamma^{T-t-1}\rho_{t:T-1}R_T
\end{align}\]
- \[\rho_{t:T-1}R_{t+1}=\frac{\pi(A_t\vert S_t)}{b(A_t\vert S_t)}\frac{\pi(A_{t+1}\vert S_{t+1})}{b(A_{t+1}\vert S_{t+1})}\frac{\pi(A_{t+2}\vert S_{t+2})}{b(A_{t+2}\vert S_{t+2})}\cdots\frac{\pi(A_{T-1}\vert S_{T-1})}{b(A_{T-1}\vert S_{T-1})}R_{t+1}\]
-
在上面的式子中,可以发现只有$\frac{\pi(A_t\vert S_t)}{b(A_t\vert S_t)}$与$R_{t+1}$是相关的,($R_{t+1}$显然只跟$t+1$时刻之前的决策有关)又
- \[\mathbb E\Big[\frac{\pi(A_k\vert S_k)}{b(A_k\vert S_k)}\Big]\overset.=\sum_a b(a\vert S_k)\frac{\pi(a\vert S_k)}{b(a\vert S_k)}=\sum_a\pi(a\vert S_k)=1\]
-
因此有
- \[\mathbb E[\rho_{t:T-1}R_{t+1}]=\mathbb E[\rho_{t:t}R_{t+1}]\]
-
类似地,对于其他项有
- \[\mathbb E[\rho_{t:T-1}R_{t+k}]=\mathbb E[\rho_{t:t+k-1}R_{t+k}]\]
-
综上
- \[\mathbb E[\rho_{t:T-1}G_t]=\mathbb E[\overset\sim G_t]\\ \overset\sim G_t=\sum_{k=t}^{T-1}\gamma^{k-t}\rho_{t:k}R_{k+1}\]
-
这种思想称为每次决策型重要度采样,对于普通重要度采样器,可以使用$\overset\sim G_t$替代$G_t$后可以保持期望不变并降低方差
- \[V(s)\overset.=\frac{\sum_{t\in\mathcal T(s)}\overset\sim G_t}{\vert\mathcal T(s)\vert}\]
-
\[\begin{align}
\rho_{t:T-1}G_t=&\rho_{t:T-1}(R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{T-t-1}R_T)\\
=&\rho_{t:T-1}R_{t+1}+\gamma\rho_{t:T-1}R_{t+2}+\cdots+\gamma^{T-t-1}\rho_{t:T-1}R_T
\end{align}\]
-
小结
- 相比DP的优点
- 不需要描述环境动态特性的模型
- 可以使用数据仿真或采样模型
- 可以简单高效地聚焦于状态的一个小的子集
- 在马尔可夫性不成立时性能损失较小(因为不需要自举)
- 相比DP的优点
Chap 6. 时序差分学习
在强化学习所有的思想中,时序差分(TD)学习无疑是最核心、最新颖的思想
- 时序差分预测
-
蒙特卡洛更新的目标是回报$G_t$,而TD更新的目标是$R_{t+1}+\gamma V(S_{t+1})$
-
蒙特卡洛方法需要等一幕结束才能计算回报来更新价值函数
- \[V(S_t)\leftarrow V(S_t)+\alpha[G_t-V(S_t)]\]
-
TD方法只需要等到下一个时刻即可
- \[V(S_t)\leftarrow V(S_t)+\alpha[R_{t+1}+\gamma V(S_{t+1})-V(S_t)]\]
- 这种TD方法被称为TD(0),或单步TD
-
由于TD(0)的更新在某种程度上基于已存在的估计,类似与DP,也称之为一种自举法
- \[\begin{align} v_\pi(s)\overset.=&\mathbb E_\pi[G_t\vert S_t=s]\\ =&\mathbb E_\pi[R_{t+1}+\gamma G_{t+1}\vert S_t=s]\\ =&\mathbb E_\pi[R_{t+1}+\gamma v_\pi(S_{t+1})] \end{align}\]
-
TD(0)括号里的数值是一种误差,被称为TD误差
- \[\delta_t\overset .=R_{t+1}+\gamma V(S_{t+1})-V(S_t)\]
-
-
时序差分预测方法的优势
- 相比DP,不需要环境模型;相比蒙特卡洛,不需要等到一幕的结束
-
TD(0)的最优性
-
Sarsa:同轨策略下的时序差分控制
-
\[Q(S_t,A_t)\leftarrow Q(S_t,A_t) + \alpha\Big[R_{t+1}+\gamma Q(S_{t+1},A_{t+1})-Q(S_t,A_t)\Big]\]
- 如果$S_{t+1}$是终止状态,那么$Q(S_{t+1},A_{t+1})$定义为$0$
- 这个更新规则用到了描述这个事件的五元组$(S_t,A_t,R_{t+1},S_{t+1},A_{t+1})$中的所有元素。我们根据这个五元组把这个算法命名为$Sarsa$
-
\[Q(S_t,A_t)\leftarrow Q(S_t,A_t) + \alpha\Big[R_{t+1}+\gamma Q(S_{t+1},A_{t+1})-Q(S_t,A_t)\Big]\]
-
Q学习:离轨策略下的时序差分控制
- \[Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha\Big[R_{t+1}+\gamma\underset a\max Q(S_{t+1},a)-Q(S_t,A_t)\Big]\]
- 动作价值函数$Q$采用了对最优动作价值函数$q_*$的直接近似作为学习目标,与行动策略是什么完全无关。
-
期望Sarsa
-
实际上是将原本的最大动作状态价值$Q(S_{t+1},A_{t+1})$改为了期望状态价值$V(S_{t+1})$
- \[\begin{align} Q(S_t,A_t)&\leftarrow Q(S_t,A_t)+\alpha\Big[R_{t+1}+\gamma \mathbb E[Q(S_{t+1},A_{t+1})\Big\vert S_{t+1}]-Q(S_t,A_t)\Big]\\ &\leftarrow Q(S_t,A_t)+\alpha\Big[R_{t+1}+\gamma \sum_a\pi(a\vert S_{t+1})Q(S_{t+1},a)-Q(S_t,A_t)\Big] \end{align}\]
-
-
最大化偏差与双学习
-
Q学习中,将$Q$估计的最大值$\underset a\max Q(S_{t+1},a)$视为对真实价值最大值的估计(最大的$Q$的估计值)会产生正偏差,将其称作最大化偏差
-
比如,令$Q(S_{t+1},a)$的真实期望都为零,方差不为零,就会有一部分$Q(S_{t+1},a)$的估计大于真实期望,对应下面的公式就是$\hat q_1\geq 0,\ \hat q_2\rightarrow 0$
- \[q_1\overset.=Q(S_{t+1},a)\\ q_2\overset.=(\underset a\max Q)(S_{t+1},a)\\ \underset a\max \hat q_1\geq \hat q_2\]
-
-
考虑避免最大化偏差
- 对于这一问题,有一种看法是,其根源在于确定价值最大的动作和估计它的价值这两个过程采用了同样的样本
- 将样本划分为两个集合,并用它们学习两个独立的对真实价值$q(a)$的估计$Q_1(a),Q_2(a)$
- 用$Q_1(a)$来确定最大的动作$A^*=\arg\max_a Q_1(a)$
- 用$Q_2(a)$来计算其价值的估计$Q_2(\arg\max_a Q_1(a))$
- 由于$\mathbb E[Q_2(A^)]=q(A^)$,上面的估计是无偏的
- 交换角色重复执行上面过程,就是双学习的思想
-
双Q学习
- \[Q_1(S_t,A_t)\leftarrow Q_1(S_t,A_t)+\alpha\Big[R_{t+1}+\gamma Q_2(S_{t+1},\underset a{\arg\max}\ Q_1(S_{t+1},a))-Q_1(S_t,A_t)\Big]\]
-
-
游戏、后位状态和其他特殊例子
- 在一些游戏中状态价值函数评估的是执行某个动作后的游戏局面,称之为后位状态(afterstates),并将它们的价值函数称之为是后位状态价值函数
- 当不同的(状态,动作)二元组到达同一个后位状态,那么就会要求这些二元组对应的动作价值函数相等,在这样的情况下使用后位状态价值函数可以规避这样的问题。
- 实际上就是应用了一些先验知识,如一些游戏的规则确定,(状态,动作)的转移就是确定的。而对于缺乏先验的情况,执行一个动作无法知道下一个状态的概率分布,也就不存在动作价值函数与状态价值函数绑定的情况。
Chap 7. n步自举法
单独的蒙特卡洛方法或时序差分方法都不会总是最好的方法。n步时序差分方法是这两种方法更一般的推广。
-
n步时序差分预测
-
n步回报
- \[G_{t:t+n}\overset.=R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\cdots+\gamma^{n-1}R_{t+n}+\gamma^nV_{t+n-1}(S_{t+n})\]
- 其中$n\geq1,\ 0\leq t<T-n$
-
更新
- \[V_{t+n}(S_t)\overset.=V_{t+n-1}(S_t)+\alpha[G_{t:t+n}-V_{t+n-1}(S_t)],\ 0\leq t<T\]
-
对于其他状态$s(s\neq S_t)$的价值估计保持不变:$V_{t+n}(S)=V_{t+n-1}(S)$
- 这个算法被称为n步时序差分(n步TD)算法
-
n步回报的误差减少性质(会逐渐收敛)
- \[\underset s\max\Big\vert\mathbb E_\pi[G_{t:t+n}\vert S_t=s]-v_\pi(s)\Big\vert\leq\gamma^n\underset s\max\Big\vert V_{t+n-1}(s)-v_\pi(S)\Big\vert\]
-
-
n步Sarsa
- 重新根据动作的价值估计定义如下n步方法的回报(更新目标)
- \[G_{t:t+n}\overset.=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{n-1}R_{t+n}+\gamma ^nQ_{t+n-1}(S_{t+n},A_{t+n}),\ n\geq1,\ 0\leq t<T-n\\ G_{t:t+n}=G_t,\ t\geq T-n\]
-
于是有
- \[Q_{t+n}(S_t, A_t)\overset.=Q_{t+n-1}(S_t,A_t)+\alpha[G_{t:t+n}-Q_{t+n-1}(S_t,A_t)],\ 0\leq t<T\]
-
这里可以使用期望Sarsa的回报形式
- \[G_{t:t+n}\overset.=R_{t+1}+\cdots+\gamma^{n-1}R_{t+n}+\gamma^n\overline V_{t+n-1}(S_{t+n}),\ t+n<T \\ \overline V_t(s)\overset.=\sum_a\pi(a\vert s)Q_t(s,a),\ \forall s\in \mathcal S\]
- 重新根据动作的价值估计定义如下n步方法的回报(更新目标)
-
n步离轨策略学习
-
使用n步方法中对回报$G_{t:t+n}$的定义,对于更新可使用$\rho_{t:t+n-1}$来加权
- \[V_{t+n}(S_t)\overset.=V_{t+n-1}(S_t)+\alpha \rho_{t:t+n-1}[G_{t:t+n}-V_{t+n-1}(S_t)],\ 0\leq t<T\\ Q_{t+n}(S_t,A_t)\overset.=Q_{t+n-1}(S_t,A_t)+\alpha\rho_{t:t+n-1}[G_{t:t+n}-Q_{t+n-1}(S_t,A_t)],\ 0\leq t<T\]
-
$\rho_{t:t+n-1}$是重要度采样率,是两种策略采取$A_t\sim A_{t+n-1}$这$n$个动作的相对概率
- \[\rho_{t:h}\overset.=\Pi_{k=t}^{\min(h,T-1)}\frac{\pi(A_k\vert S_k)}{b(A_k\vert S_k)}\]
-
-
带控制变量的每次决策型方法
-
在前面的n步方法中,如果出现$\rho_t=0$,则$n$步回报为$0$(所有$\rho_{t:t+k}$都包含$\rho_t$),会导致错误的更新
-
原n步回报(带重要度加权)
- \[G_{t:h}=\rho_t(R_{t+1}+\gamma G_{t+1:h}),\ t<h<T\\ G_{h:h}\overset.=V_{h-1}(S_h)\]
-
修改为(其中$(1-\rho_t)V_{h-1}(S_t)$的期望为$0$)
- \[G_{t:h}\overset.=\rho_t(R_{t+1}+\gamma G_{t+1:h})+(1-\rho_t)V_{h-1}(S_t),\ t<h<T\\ G_{h:h}\overset.=V_{h-1}(S_h)\]
- 其中,$(1-\rho_t)V_{h-1}(S_t)$被称为控制变量
-
显然,在修改之后,如果$\rho_t=0$,回报不会为0而导致估计值收缩
-
-
对于动作价值而言,使用控制变量的离轨策略形式可以为
- \[G_{t:h}\overset .=R_{t+1}+\gamma\rho_{t+1}\Big(G_{t+1:h}-Q_{h-1}(S_{t+1},A_{t+1})\Big)+\gamma \overline V_{h-1}(S_{t+1}),\ t<h\leq T\]
-
如果$h<T$则上面的递归公式结束于$G_{h:h}\overset.=Q_{h-1}(S_h,A_h)$;若$h\geq T$,则结束于$G_{T-1:h}=R_T$
- 由此得出的预测算法是期望Sarsa的扩展($\gamma\rho_{t+1}\Big(G_{t+1:h}-Q_{h-1}(S_{t+1},A_{t+1})\Big)$期望为零)
-
-
不需要重要度采样的离轨学习方法:n步树回溯算法
-
综合考虑每个状态下没有被选择的所有动作,因此不再需要重要度采样
-
树回溯的n步回报
- \[G_{t:t+n}\overset.=R_{t+1}+\gamma \sum_{a\neq A_{t+1}}\pi(a\vert S_{t+1})Q_{t+n-1}(S_{t+1},a)+\gamma\pi(A_{t+1}\vert S_{t+1})G_{t+1:t+n}\\ G_{T-1:t+n}\overset.=R_T\]
-
-
-
一个统一的算法:n步$Q(\sigma)$
-
思想:对状态逐个决定是否要采取采样操作,即使用重要度采样/直接考虑所有可能动作的期望
- 如果总是采样,就是Sarsa算法,如果总是不采样,就是树回溯算法;期望Sarsa就是只在最后一步不采样
-
若使用采样,回报为:(对动作价值的使用控制变量离轨策略形式回报)
- \[G_{t:h}\overset .=R_{t+1}+\gamma\rho_{t+1}\Big(G_{t+1:h}-Q_{h-1}(S_{t+1},A_{t+1})\Big)+\gamma \overline V_{h-1}(S_{t+1})\]
-
若不使用采样,回报为:
- \[\begin{align} G_{t:h}\overset.=&R_{t+1}+\gamma \sum_{a\neq A_{t+1}}\pi(a\vert S_{t+1})Q_{h-1}(S_{t+1},a)+\gamma \pi(A_{t+1}\vert S_{t+1})G_{t+1:h}\\ =&R_{t+1}+\gamma\pi(A_{t+1}\vert S_{t+1})\Big(G_{t+1:h}-Q_{h-1}(S_{t+1},A_{t+1})\Big)+\gamma \overline V_{h-1}(S_{t+1}) \end{align}\]
-
可以很自然地将两者进行线性组合
- \[G_{t:h}\overset.=R_{t+1}+\gamma\Big(\sigma_{t+1}\rho_{t+1}+(1-\sigma_{t+1})\pi(A_{t+1}\vert S_{t+1})\Big)\Big(G_{t+1:h}-Q_{h-1}(S_{t+1},A_{t+1})\Big)+\gamma\overline V_{h-1}(S_{t+1})\]
-
Chap 8. 基于表格型方法的规划和学习
本章的目标是将基于模型的方法和无模型的方法整合起来
- 模型和规划
- 分布模型:生成对所有可能结果的描述及对应概率分布
- 样本模型:生成一个从概率分布采样得到的确定结果
- 规划:以环境模型为输入,生成或改进与它进行交互的策略的计算过程
- Dyna:规划、动作、学习的集成
- 无模型:直接强化学习;有模型:间接强化学习
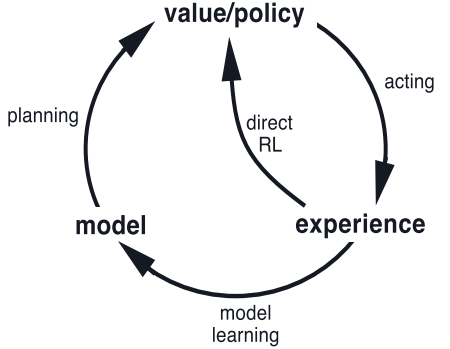
- 一般的Dyna架构,真正的经验在环境和策略之间来回传递,影响策略和价值函数
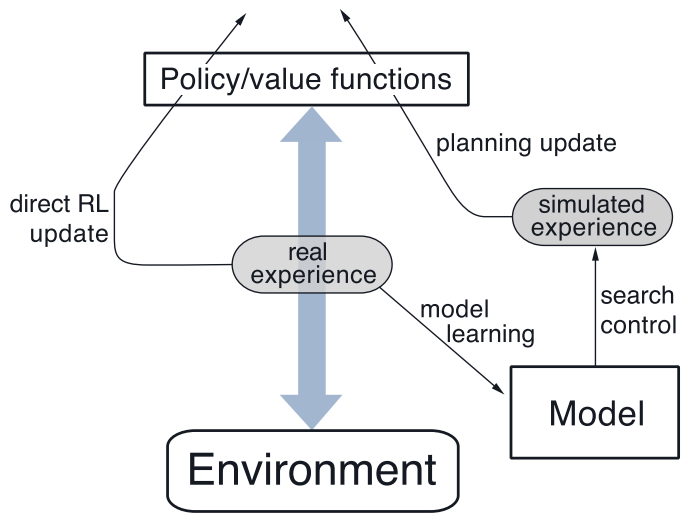
- 在前面章节中,只是从真实采样结果来求解价值函数,这是无模型的方法;可以结合有模型的方法进行实现,也就是在每得到一个采样之后都进行n次模拟(这个过程就是规划),对于每次模拟
- 随机选择之前观察到的一个状态
- 随机选择之前在该状态下采取过的动作
- 然后以此回溯更新
- 模型与真实环境存在误差
- 试探:要尝试某些可能改善模型的动作
- 开发:以当前模型的最优方式执行动作
- 记录(状态,动作)二元组距上次出现经过了多长时间,时间越长越有理由相信该二元组的环境动态特性会发生变化
- 实践上可以添加额外收益$\kappa\sqrt \tau$
- 优先遍历
- 在许多场景下,均匀采样的效率是非常低的
- 确定性环境下的优先级遍历算法
- 每一步更新会有“状态-动作”二元组以及价值绝对值的改变
- 如果大于某个阈值,则将(状态,动作)以及价值改变插入优先队列(价值改变大的优先级高)
- 在采样之后的n次模拟中
- 取出优先队列队首,找到所有前导(状态,动作)进行更新
- 期望更新与采样更新的对比
- 轨迹采样
- 通过模拟仿真得到独立且明确的完整智能体运行轨迹,并对沿途遇到的状态或(状态,动作)二元组执行回溯更新。我们称这种借助模拟生成经验来进行回溯更新的方法为轨迹采样
- 实时动态规划
- 是动态规划价值迭代算法的同轨策略采样版本
- 是异步DP的一个例子
- RTDP可以保证找到相关状态下的最优策略,而无需频繁访问每个状态
- 决策时规划
- 前面提到的规划方式是在得到回报和新的状态后选择动作前进行n步模拟
- 是使用模拟经验来逐步改进策略或价值函数
- 称为后台规划
- 另一种方式是在每次得到新状态之后通过规划输出单个动作
- 一种简单实现:对于每个可选的动作,可以通过环境模型预测后继状态的价值,通过比较这些价值来进行动作选择
- 称为决策时规划
- 前面提到的规划方式是在得到回报和新的状态后选择动作前进行n步模拟
- 启发式搜索
- 类似决策时规划
- 预演(rollout)算法
- 一种基于蒙特卡洛控制的决策时规划算法
- 通过平均许多起始于每一个可能的动作并遵循给定策略的模拟轨迹的回报来估计动作价值
- 预演算法的目标不是估计一个最优动作价值函数,而仅在当前状态下根据预演策略做出动作价值的蒙特卡洛估计
- 蒙特卡洛树搜索
- 一个基本的MCTS的每一次循环中包含下面四个步骤:
- 选择。从根节点开始,使用基于树边缘的动作价值的树策略遍历这棵树来挑选一个叶子节点
- 扩展。在某些循环中(根据应用的细节决定),针对选定的叶子节点找到采取非试探性动作可以到达的节点,将一个或多个这样的节点加为该叶子节点的子节点,以此来实现树的扩展
- 模拟。从选定的节点,或其中一个它新增加的子节点(如果存在)出发,根据预演策略选择动作进行整幕的轨迹模拟。得到的结果是—个蒙特卡洛实验,其中动作首先由树策略选取,而到了树外则由预演策略选取。
- 回溯。模拟整幕轨迹得到的回报值向上回传,对在这次MCTS循环中,树策略所遍历的树边缘上的动作价值进行更新或初始化。预演策略在树外部访问到的状态和动作的任何值都不会被保存下来。
- 一个基本的MCTS的每一次循环中包含下面四个步骤: